Optimizing Speech Synthesis for Global Scale
High-fidelity audio generation usually comes with a massive compute cost that stalls deployment in enterprise environments. Most current architectures require expensive clusters of high-end GPUs just to maintain acceptable latency for user-facing applications. This hardware bottleneck makes it difficult to adopt high-speed voice cloning models for production across distributed global teams. When your infrastructure costs grow linearly with your user base, the financial math for synthetic media starts to break down quickly.
Searching for a solution that handles latency and cost better led me to LuxTTS, an open-source voice cloning model by Yatharth Sharma. I spent time testing how it handles different accents and audio qualities, and it stands out because it prioritizes efficiency without making the output sound robotic. For technical teams building digital transformation initiatives without ballooning their AWS or Azure bill, this lightweight approach addresses a critical gap in the current TTS landscape.
Scalability with High-Speed Voice Cloning Models for Production
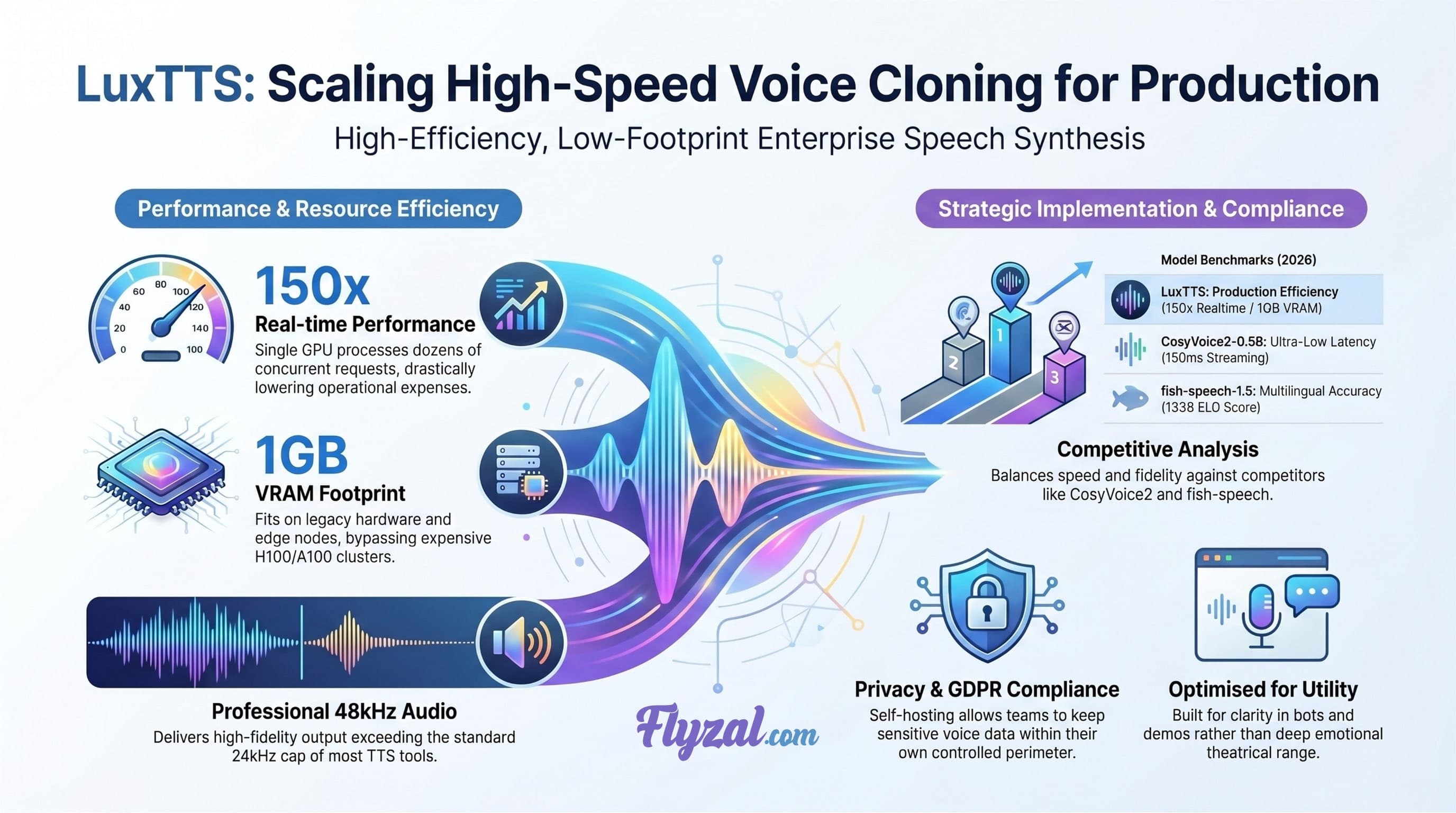
Performance at scale is the primary metric for any ML engineering team evaluating TTS solutions. LuxTTS reaches speeds exceeding 150x realtime on a single GPU, which is a significant leap over heavier, non-distilled models. This speed isn't just a vanity metric — it means a single server can handle dozens of concurrent requests that would normally require a dedicated hardware stack. In an enterprise setting, this translates directly to lower operational expenses and a smaller carbon footprint, aligning with increasingly strict environmental and social governance (ESG) reporting requirements.
Technical leaders should pay attention to the memory footprint: the model fits within 1GB of VRAM. This allows for deployment on legacy hardware or smaller edge nodes, which is critical for companies operating in regions where the latest H100 or A100 chips are unavailable or cost-prohibitive. By moving inference closer to the user on less expensive hardware, you reduce data egress costs and latency, providing a better experience for customers in ASEAN or GCC regions who might be far from central data hubs.
Among lightweight voice cloning models optimized for edge deployment in 2026, LuxTTS balances speed and audio fidelity effectively. Competing models like CosyVoice2-0.5B achieve 150ms ultra-low latency streaming, while fish-speech-1.5 leads in multilingual accuracy with an ELO score of 1339. LuxTTS differentiates itself through its compact size (1GB VRAM), high sample rate (48kHz), and CPU compatibility (1-8x realtime even on CPU).
Audio Quality and Compliance Standards
Speed often trades off with quality, but LuxTTS outputs 48kHz audio. Most standard text-to-speech tools are capped at 24kHz, resulting in a muffled or artificial sound. Using higher sample rates ensures that the generated voice maintains professional clarity, which is essential for brand consistency in global marketing campaigns and customer-facing applications.
From a risk management perspective, self-hosting this open-source model locally or in a private cloud environment allows you to align with NIST AI Risk Management Framework and GDPR-equivalent data residency requirements. You keep the voice data and the processing within your own controlled perimeter, avoiding the security and compliance pitfalls of sending sensitive audio to third-party APIs.
The Technical Trade-offs
Every tool has its limits, and LuxTTS is no exception. While it's incredibly fast, it lacks the deep emotional range found in much larger, multi-billion parameter models. If you're building a tool for theatrical performances or high-drama audiobooks, this might not be the right choice. It's built for utility, speed, and clarity — use cases like customer support bots, internal training materials, accessibility tools, and product demos.
Additionally, while the installation is straightforward for teams familiar with Python and PyTorch, enterprise teams working exclusively in C# or Java will need to build their own wrappers or API layers to integrate this into existing service-oriented architectures.
LuxTTS is an open-source research model, not a commercial product. It doesn't come with enterprise support, SLAs, or compliance certifications out of the box. Teams adopting it need in-house ML engineering capacity to deploy, monitor, and maintain the model in production.
Getting Started
Repository: https://github.com/ysharma3501/LuxTTS
Model on Hugging Face: https://huggingface.co/YatharthS/LuxTTS
Hosted API (fal.ai): https://fal.ai/models/fal-ai/lux-ttsfal
I build free and paid tools at flyzal.com that put these ideas into practice. Access requires an account, with fast sign-in via Google or GitHub. I also work with companies that want these concepts turned into production-ready software for their teams.